Jul 05, 2024
A Comprehensive Guide to OpenTelemetry
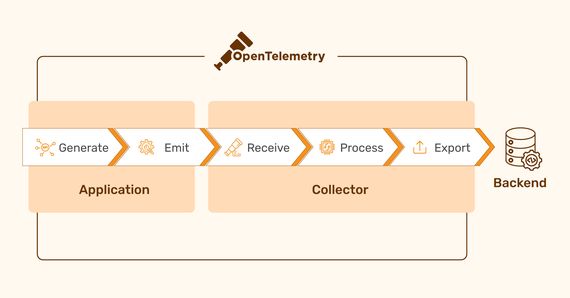
Modern software development often leverages distributed architectures to achieve faster development cycles …


Just within the past year, we have seen an explosion in the release of new machine learning models that utilize novel techniques and methods to achieve specific and/or general tasks. Models such as OpenAI’s ChatGPT have taken front-and-center stage, pushing other models to the back. Within these other, still reputable models, exists stable diffusion. Let’s take a shallow dive into what this model is, how it works, and why it’s so contested.
Initially released on August 22, 2022 , stable diffusion is a deep learning product of Stability AI used to generate images from text input. A user simply has to give a prompt about the image to generate, and the diffusion model will generate the image over a series of steps. Each step will create a better version of the previous image. Sometimes, objects within the image might change, however, the images themselves will improve in quality. These ‘improvements in quality’ can be attributed to less noise in the images.
Stable diffusion works on the principle of diffusion.
Diffusion: Literally means to ‘spread something widely’.
However, in our case, it means to subtly add noise to an image over a series of steps. For example, consider how
gaussian noise is added to the image below:
 The diffusion (noise) was slowly added over 100 steps. As you can tell, we have added enough noise to make the photo
become a full noise photo. What if we created a model to reverse the process? This model would take a noisy image as an
input, and then generate a clear image as an output. This is pretty much exactly the reverse process:
The diffusion (noise) was slowly added over 100 steps. As you can tell, we have added enough noise to make the photo
become a full noise photo. What if we created a model to reverse the process? This model would take a noisy image as an
input, and then generate a clear image as an output. This is pretty much exactly the reverse process:
 This is exactly what stable diffusion accomplishes. If we train the model good enough, we do not have to have the noise
that was generated from the original image. We can just use random noise as the input, and create an image from it!
This is exactly what stable diffusion accomplishes. If we train the model good enough, we do not have to have the noise
that was generated from the original image. We can just use random noise as the input, and create an image from it!
Let’s look at it intuitively. Assuming the models goal is to work backwards, at each iteration, the model will take away
all the noise in the input image, keep one step’s worth of noise, and return all the other noise back to the image. Now,
if you think about it, the image has arrived at the previous step in the process of diffusion, getting more and more
clear with each iteration.
Stable diffusion made waves when it came out, because of its sheer capability, and all of the benefits associated with it:
As there always is with a new technology, there exists opposition to the stable diffusion model. The outcry in the cases listed below might be a bit more justified, however. Since this model is used to generate pictures, obviously there will be some instances where people will use the ‘art’ generated by the model to gain money/fame:
Both instances have got artists fuming, as most people (especially the judges) could not tell if an image was generated
or not. Of course, they have a right to be concerned about AI intervening in the art department. Just take a look at the
stable diffusion generated image below:


Hannan Khan holds a Masters in Computer Science from UT Arlington, with a specialization in Intelligent Systems. His passions include …
Modern software development often leverages distributed architectures to achieve faster development cycles …
Let's look at a human analogy to better understand what Transfer Learning is and how to use it. Imagine in a …


In programming, the concept of a one-size-fits-all language is a fallacy. Different languages offer …
Finding the right talent is pain. More so, keeping up with concepts, culture, technology and tools. We all have been there. Our AI-based automated solutions helps eliminate these issues, making your teams lives easy.
Contact Us